SET FUNKSIYALAR
UNION
UNION funksiyasi bir ve ya bir nece tablonu alt alta birlesdirmek ucun istifade edilir.Sintaksisi asagidaki kimdir :
UNION(<tablo_ifadəsi>, <tablo_ifadəsi>, [,<tablo_ifadəsi>]…)
Nəticə:
“Bakı” deyəri hər iki tabloda yer aldığından döndərilən nəticə tabloda da təkrarlanan sətirlər olaraq qarşımıza çıxır. Bu kimi hallarda DISTINCT DAX funksiyasından istifadə edərək dublikat sətirləri aradan qaldıra bilərsiniz:
Nəticə:
INTERSECT
INTERSECT DAX funksiyası iki tablonun kəsişməsini döndərən DAX funksiyasıdır. UNION-dan fərqli olaraq, iki tablo ifadəsi tələb edir:
INTERSECT(<tablo_ifadəsi1>, <tablo_ifadəsi2>)
EXCEPT DAX funksiyası birinci tablonun sətirlərini döndərir, hansı ki, həmin sətirlər ikinci tabloda mövcud deyildir. Bu funksiyada öz növbəsində iki tablo ifadəsi tələb edir.
Set funksiyaları data lineage mövzusunda fərqli davranışlar sərgiləyirlər. Əgər data lineage mövzusuna yadınızdırsa, bu mövzu haqqında yazıya nəzər sala bilərsiniz.
UNION vasitəsilə döndərilən tablonun sütunları o zaman data lineage-ə sahib olur ki, birləşdirilən sütunlar eyni data lineage-ə sahib olsun. Məsələn:
Yuxarıdakı koda nəzər salsanız, UNION-un hər iki arqumenti kodumuz asan və oxunaqlı olsun deyə dəyişkən (VAR) içərisində yaradılıb. Birinci arqument yeni "Prm1" VALUES(Date[Year]) və VALUES(Customer[Customer Key]) tablolarının CROSSJOIN vasitəsilə birləşməsindən yaranmışdır. CROSSJOIN arqumentdə göstərilən tabloların bütün mümkün kombinasiyalarından (Cartesian product) ibarət nəticə tablosu döndərir. Məqaləmiz CROSSJOIN haqqında deyil, lakin gələcəkdə bu mövzu ilə bağlı bir məqalə hazırlamağı planlayırıq. Lakin, böyük datalarla işləyərkən, CROSSJOIN performansa əhəmiyyətli dərəcədə təsir göstərə bilər. Buna görə də, bu funksiyadan istifadə edərkən potensial ağırlaşmaları diqqətə almanızı tövsiyə edirik. Neyse ki, CROSSJOIN funksiyasının qaytardığı tablonu "Prm1" olaraq adlandırdıq və bu tablonun birinci sütunu 'Date[Year]', ikinci sütunu 'Customer[Key]' sütununun data lineage’ni daşıyır. "Prm2" dəyişkəni içərisində yaradılan tablolar isə tablo konstruktoru ilə yaradılan statik tablolardır. Statik tablolar modelə aid olmadığından data lineage’ə sahib olmur, lakin, bizim əlimizdə güclü silah var - TREATAS. Data lineage haqqında məqalədə nə işə yaradığı barədə məlumat vermişdik. TREATAS vasitəsilə statik tabloların data lineage’ni dəyişdirdik. Beləliklə, "Prm1" və "Prm2" tablolarının birinci sütunu Date[Year] sütununun, ikinci sütunu Customer[Customer Key] sütunun data lineage’ni daşıyır. Nəticə olaraq, UNION vasitəsilə birləşdirilən tabloların sütunları eyni data lineage-ə sahib olduqlarına görə "UnionTablosu"nun hər iki sütunu data lineage’ə sahibdir və 'Sales' tablosuna hər iki sütundan filter yayıla bilir:

Indi ise aşağdaki koda baxin:
Bu dəfə "Prm2" tablosunda TREATAS istifadə etmədik, "Prm1" və "Prm2" tablolarının ikinci sütununun data lineage’i eynidir - Customer[Customer Key]. Lakin, "Prm1" tablosunun birinci sütunu Date[Year] sütununun data lineage’ni daşısa da, "Prm2" tablosunun birinci sütunu statik tabloya aid olduğuna görə data lineage’ə sahib deyil. Buna görə də, "UnionTablosu"nun ikinci sütunu Customer[Customer Key] sütununun data lineage’ni daşıyacaq, ikinci sütununun isə data lineage’i olmayacaq. Beləliklə, filter axışında yalnız birinci sütunun dəyərləri iştirak edəcək və 'Sales' tablosuna yalnız birinci sütundan filter yayılacaq:

INTERSECT vasitəsilə döndərilən tablo isə yalnız birinci tablonun sütunlarının data lineage’ni daşıyır. Eyni şeyi EXCEPT haqqında da demək olar. Məsələn, modelə nəzər salsanız görərsiniz ki, 'Target Table' adında hədəf tablomuz var və bu tablonun modeldə heç bir tablo ilə əlaqəsi yoxdur.Dolayısıyla normal şərtlər altında 'Target Table' sütunlarında olan filter 'Sales' tablosuna yayılmır. Amma bu cür güclü konseptlərə hakim olsanız, bu qanunlar sizin üçün deyil. Tamam, deyək ki, bizə bütün illərin yox, yalnız hədəfi olan illərin satış rəqəmləri lazımdır. Belə bir kod yazsaq işə yaramayacaq.

Göründüyü kimi, kod hər bir sətir üçün eyni dəyərləri gətirdi. Bu, ondan irəli gəlir ki, 'Target Table' ilə 'Sales' tablosu arasında heç bir fiziki aktiv əlaqə olmadığından, filter axisi baş vermədi.İndi isə DAX’ın gücünə baxın:

Nəticə doğrudur. INTERSECT iki tablonun kəsişməsini döndərdi, şübhəsiz bizə lazım olan bu idi, qaytarılan illər həm ‘Date’ tablosunda yer alır, həm də ‘Target Table’ da. Məsələn, “2018” deyəri ‘Target Table’ da olmadığına görə tabloda yer almir. He, o ki qaldi filter axışına, INTERSECT həmişə birinci tablonun data lineage’ni miras alır. Yəni “TabloInt” blokunda qaytarılan tablo ‘Date[Year]’ sütunun data lineage’ni daşıyır. ‘Date’ tablosu ilə ‘Sales’ tablosu arasında one-to-many fiziki aktiv əlaqə olduğuna görə il sütununda olan filter ‘Sales’ tablosuna yayılabilir.
Bu məqalədə həm set funksiyalarının işleyiş məntiqini oxucularımıza çatdırmaq istədik, həm də data lineage mövzusunun önəmini bir daha vurğulamış olduq. Set funksiyalar sintaksis cəhətdən sadə olsalar da, geniş istifadə diapazonuna sahibdirlər. Düzgün istifadə edildiyi təqdirdə optimal nəticələr əldə edə bilərsiniz.
Faylı yükləmək üçün aşağıdakı linkə keçid edin


UNION funksiyasi bir ve ya bir nece tablonu alt alta birlesdirmek ucun istifade edilir.Sintaksisi asagidaki kimdir :
UNION(<tablo_ifadəsi>, <tablo_ifadəsi>, [,<tablo_ifadəsi>]…)
- Öncəliklə bilmək lazımdır ki, hər bir tablonun sütun sayıları eyni olmalıdır.
- Sütunlar, tablolardakı yerinə görə birləşdirilir. Yəni, birinci tablodakı birinci sütun uyğun olaraq, ikinci tablodakı birinci sütunla birləşdirilir.
- Döndərilən tablodakı sütunlar birinci tablodakı sütun adlarını daşıyır.
- Döndərilən tablo genişlədilmiş tablo deyil və əlaqəli sütunları özündə ehtiva etmir.
- Bir və ya bir neçə tablo alt-alta birləşdirildikdə, təkrarlanan sətirlər toxunulmaz qalır. Əgər təkrarlanan sətirləri aradan qaldırmaq istəyirsinizsə, DISTINCT DAX funksiyasından istifadə edə bilərsiniz.
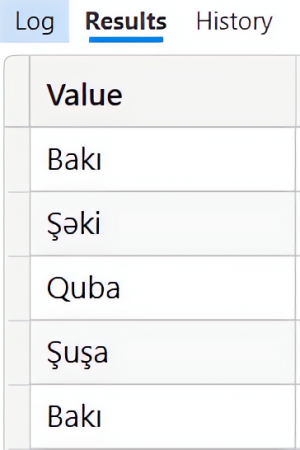
| EVALUATE UNION( VAR Tablo1 = {"Bakı","Şəki"} RETURN Tablo1, VAR Tablo2 = {"Quba","Şuşa","Bakı"} RETURN Tablo2) |
Nəticə:
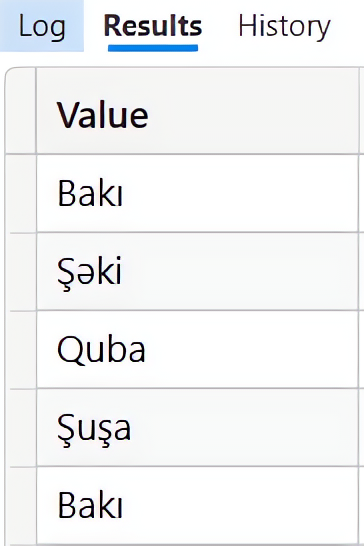
“Bakı” deyəri hər iki tabloda yer aldığından döndərilən nəticə tabloda da təkrarlanan sətirlər olaraq qarşımıza çıxır. Bu kimi hallarda DISTINCT DAX funksiyasından istifadə edərək dublikat sətirləri aradan qaldıra bilərsiniz:
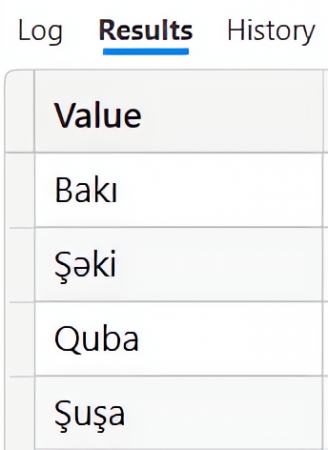
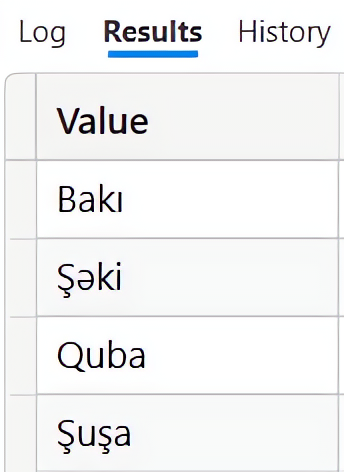
| EVALUATE DISTINCT(UNION( VAR Tablo1 = {"Bakı","Şəki"} RETURN Tablo1, VAR Tablo2 = {"Quba","Şuşa","Bakı"} RETURN Tablo2)) |
Nəticə:
INTERSECT
INTERSECT DAX funksiyası iki tablonun kəsişməsini döndərən DAX funksiyasıdır. UNION-dan fərqli olaraq, iki tablo ifadəsi tələb edir:
INTERSECT(<tablo_ifadəsi1>, <tablo_ifadəsi2>)
- Birinci və ikinci arqumentin yerləri dəyişdikdə fərqli nəticələr ala bilərsiniz, çünki təkrarlanan sətirlər toxunulmaz qalır.
- Sütunlar tablolardakı yerlərinə görə birləşdirilir. Yəni, birinci tablodakı birinci sütun uyğun olaraq ikinci tablodakı birinci sütunla birləşdirilir.
- Döndərilən tablodakı sütunlar birinci tablodakı sütun adlarını daşıyır.
- Sütunların data tipləri fərqli olarsa, yazdığınız kod xəta verə bilər.
- Döndərilən tablodakı sütunlar birinci tablodakı sütun adlarını daşıyır.
- Döndərilən tablo genişləndirilmiş tablo deyil və əlaqəli sütunları özündə ehtiva etmir.
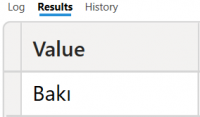
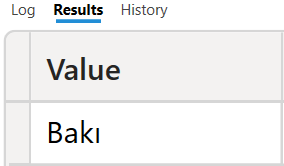
| EVALUATE INTERSECT( VAR Tablo1 = {"Bakı","Şəki"} RETURN Tablo1, VAR Tablo2 = {"Quba","Şuşa","Bakı"} RETURN Tablo2) |
Nəticə:
EXCEPT
EXCEPT DAX funksiyası birinci tablonun sətirlərini döndərir, hansı ki, həmin sətirlər ikinci tabloda mövcud deyildir. Bu funksiyada öz növbəsində iki tablo ifadəsi tələb edir.
EXCEPT(<tablo_ifadəsi1>, <tablo_ifadəsi2>)
- Sütunlar tablolardakı yerlərinə görə birləşdirilir. Yəni, birinci tablodakı birinci sütun uyğun olaraq ikinci tablodakı birinci sütunla birləşdirilir.
- Döndərilən tablodakı sütunlar birinci tablodakı sütun adlarını daşıyır.
- Sütunların data tipləri fərqli olarsa, yazdığınız kod xəta verə bilər.
- Döndərilən tablodakı sütunlar birinci tablodakı sütun adlarını daşıyır.
- Döndərilən tablo genişləndirilmiş tablo deyil və əlaqəli sütunları özündə ehtiva etmir.
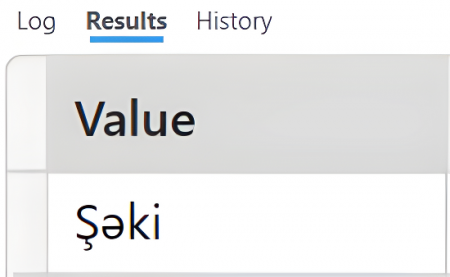
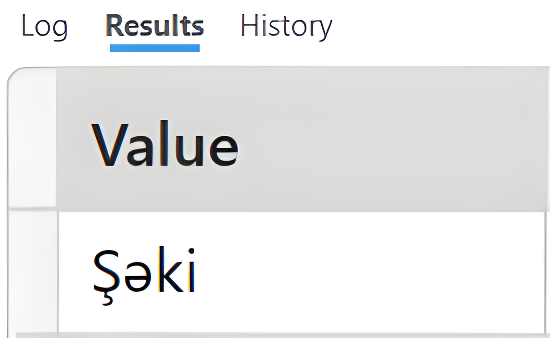
| EVALUATE EXCEPT( VAR Tablo1 = {"Bakı","Şəki"} RETURN Tablo1, VAR Tablo2 = {"Quba","Şuşa","Bakı"} RETURN Tablo2) |
DATA LINEAGE VƏ SET FUNKSİYALAR
Set funksiyaları data lineage mövzusunda fərqli davranışlar sərgiləyirlər. Əgər data lineage mövzusuna yadınızdırsa, bu mövzu haqqında yazıya nəzər sala bilərsiniz.
UNION vasitəsilə döndərilən tablonun sütunları o zaman data lineage-ə sahib olur ki, birləşdirilən sütunlar eyni data lineage-ə sahib olsun. Məsələn:
| EVALUATE VAR Prm1 = CROSSJOIN ( VALUES ( 'Date'[Year] ), VALUES ( Customer[Customer Key] ) ) VAR Prm2 = CROSSJOIN ( TREATAS ( { "2006" }, 'Date'[Year] ), TREATAS ( { 1 }, Customer[Customer Key] ) ) VAR UnionTablosu = UNION ( Prm1, Prm2 ) RETURN DISTINCT ( ADDCOLUMNS ( UnionTablosu, "Satismiqdari", FIXED ( CALCULATE ( SUM ( Sales[Amount] ) ), 1, 0 ) ) ) ORDER BY 'Date'[Year], Customer[Customer Key] |
Yuxarıdakı koda nəzər salsanız, UNION-un hər iki arqumenti kodumuz asan və oxunaqlı olsun deyə dəyişkən (VAR) içərisində yaradılıb. Birinci arqument yeni "Prm1" VALUES(Date[Year]) və VALUES(Customer[Customer Key]) tablolarının CROSSJOIN vasitəsilə birləşməsindən yaranmışdır. CROSSJOIN arqumentdə göstərilən tabloların bütün mümkün kombinasiyalarından (Cartesian product) ibarət nəticə tablosu döndərir. Məqaləmiz CROSSJOIN haqqında deyil, lakin gələcəkdə bu mövzu ilə bağlı bir məqalə hazırlamağı planlayırıq. Lakin, böyük datalarla işləyərkən, CROSSJOIN performansa əhəmiyyətli dərəcədə təsir göstərə bilər. Buna görə də, bu funksiyadan istifadə edərkən potensial ağırlaşmaları diqqətə almanızı tövsiyə edirik. Neyse ki, CROSSJOIN funksiyasının qaytardığı tablonu "Prm1" olaraq adlandırdıq və bu tablonun birinci sütunu 'Date[Year]', ikinci sütunu 'Customer[Key]' sütununun data lineage’ni daşıyır. "Prm2" dəyişkəni içərisində yaradılan tablolar isə tablo konstruktoru ilə yaradılan statik tablolardır. Statik tablolar modelə aid olmadığından data lineage’ə sahib olmur, lakin, bizim əlimizdə güclü silah var - TREATAS. Data lineage haqqında məqalədə nə işə yaradığı barədə məlumat vermişdik. TREATAS vasitəsilə statik tabloların data lineage’ni dəyişdirdik. Beləliklə, "Prm1" və "Prm2" tablolarının birinci sütunu Date[Year] sütununun, ikinci sütunu Customer[Customer Key] sütunun data lineage’ni daşıyır. Nəticə olaraq, UNION vasitəsilə birləşdirilən tabloların sütunları eyni data lineage-ə sahib olduqlarına görə "UnionTablosu"nun hər iki sütunu data lineage’ə sahibdir və 'Sales' tablosuna hər iki sütundan filter yayıla bilir:

Indi ise aşağdaki koda baxin:
| EVALUATE VAR Prm1 = CROSSJOIN ( VALUES ( 'Date'[Year] ), VALUES ( Customer[Customer Key] ) ) VAR Prm2 = CROSSJOIN ( { "2006" }, VALUES ( Customer[Customer Key] ) ) VAR UnionTablosu = UNION ( Prm1, Prm2 ) RETURN ADDCOLUMNS ( UnionTablosu, "Satismiqdari", CALCULATE ( SUM ( Sales[Amount] ) ) ) |
Bu dəfə "Prm2" tablosunda TREATAS istifadə etmədik, "Prm1" və "Prm2" tablolarının ikinci sütununun data lineage’i eynidir - Customer[Customer Key]. Lakin, "Prm1" tablosunun birinci sütunu Date[Year] sütununun data lineage’ni daşısa da, "Prm2" tablosunun birinci sütunu statik tabloya aid olduğuna görə data lineage’ə sahib deyil. Buna görə də, "UnionTablosu"nun ikinci sütunu Customer[Customer Key] sütununun data lineage’ni daşıyacaq, ikinci sütununun isə data lineage’i olmayacaq. Beləliklə, filter axışında yalnız birinci sütunun dəyərləri iştirak edəcək və 'Sales' tablosuna yalnız birinci sütundan filter yayılacaq:

INTERSECT vasitəsilə döndərilən tablo isə yalnız birinci tablonun sütunlarının data lineage’ni daşıyır. Eyni şeyi EXCEPT haqqında da demək olar. Məsələn, modelə nəzər salsanız görərsiniz ki, 'Target Table' adında hədəf tablomuz var və bu tablonun modeldə heç bir tablo ilə əlaqəsi yoxdur.Dolayısıyla normal şərtlər altında 'Target Table' sütunlarında olan filter 'Sales' tablosuna yayılmır. Amma bu cür güclü konseptlərə hakim olsanız, bu qanunlar sizin üçün deyil. Tamam, deyək ki, bizə bütün illərin yox, yalnız hədəfi olan illərin satış rəqəmləri lazımdır. Belə bir kod yazsaq işə yaramayacaq.
| EVALUATE ADDCOLUMNS( SUMMARIZE( 'Target Table', 'Target Table'[Year] ), "Satismiqdari", CALCULATE(SUM(Sales[Quantity])) ) |

Göründüyü kimi, kod hər bir sətir üçün eyni dəyərləri gətirdi. Bu, ondan irəli gəlir ki, 'Target Table' ilə 'Sales' tablosu arasında heç bir fiziki aktiv əlaqə olmadığından, filter axisi baş vermədi.İndi isə DAX’ın gücünə baxın:
| EVALUATE ADDCOLUMNS ( VAR tabloDate = SUMMARIZE ( 'Date', 'Date'[Year] ) VAR tabloTarget = SUMMARIZE ( 'Target Table', 'Target Table'[Year] ) VAR TabloInt = INTERSECT ( tabloDate, tabloTarget ) RETURN TabloInt, "Satismiqdari", CALCULATE ( SUM ( Sales[Quantity] ))) |

Nəticə doğrudur. INTERSECT iki tablonun kəsişməsini döndərdi, şübhəsiz bizə lazım olan bu idi, qaytarılan illər həm ‘Date’ tablosunda yer alır, həm də ‘Target Table’ da. Məsələn, “2018” deyəri ‘Target Table’ da olmadığına görə tabloda yer almir. He, o ki qaldi filter axışına, INTERSECT həmişə birinci tablonun data lineage’ni miras alır. Yəni “TabloInt” blokunda qaytarılan tablo ‘Date[Year]’ sütunun data lineage’ni daşıyır. ‘Date’ tablosu ilə ‘Sales’ tablosu arasında one-to-many fiziki aktiv əlaqə olduğuna görə il sütununda olan filter ‘Sales’ tablosuna yayılabilir.
Bu məqalədə həm set funksiyalarının işleyiş məntiqini oxucularımıza çatdırmaq istədik, həm də data lineage mövzusunun önəmini bir daha vurğulamış olduq. Set funksiyalar sintaksis cəhətdən sadə olsalar da, geniş istifadə diapazonuna sahibdirlər. Düzgün istifadə edildiyi təqdirdə optimal nəticələr əldə edə bilərsiniz.
Faylı yükləmək üçün aşağıdakı linkə keçid edin
Oxşar mövzular


Şərhlər (0)